
Jedes Unternehmen sammelt Daten über sein Geschäft, aber nicht jedes Unternehmen nutzt sie. Untersuchungen zeigen, dass Unternehmen, die ihre Daten analysieren und auf dieser Grundlage Entscheidungen treffen, um 6 % schneller wachsen, als es ohne diese Analyse zu erwarten wäre.
Aus den von den meisten Unternehmen gesammelten Daten lassen sich leicht Informationen darüber ablesen, wie jede einzelne Kennzahl eingestuft wird. Dies ist ein wertvolles Wissen, aber es bietet keine direkte Unterstützung für die Entscheidungsfindung des Managements.
Die Produktverkäufe eines Unternehmens sind im laufenden Quartal um 20 % gestiegen, aber wissen wir, warum das so ist? Ohne Data Science können wir nur Annahmen treffen, die auf Expertenwissen beruhen, aber ein echter Wettbewerbsvorteil entsteht, wenn man Gewissheit auf der Grundlage konkreter Daten hat. Und das ist die eigentliche Aufgabe der Datenwissenschaft.
Definition von Data Science in einfachen Worten
Data Science ist ein Begriff, der alle wissenschaftlichen Methoden im Rahmen der Datenanalyse umfasst, dank derer aus einer scheinbar nutzlosen Datenbank wertvolle Erkenntnisse gewonnen werden können. Ein Datenwissenschaftler oder Data Scientist verwendet für diese Zwecke spezielle Data-Mining-Algorithmen, maschinelle Lernmodelle (eng. machine learning) und künstliche Intelligenz (KI). Diese Algorithmen sind so konzipiert, dass sie den Datensatz bereinigen und angemessen strukturieren, dann die Muster und Beziehungen zwischen den Daten untersuchen und Schlussfolgerungen ziehen.
Warum nutzen Unternehmen Data Science?
Der Zweck, für den Data Science eingesetzt wird, kann die Suche nach neuen Gewinnquellen sein. Ein gutes Beispiel ist die Identifizierung der am häufigsten zusammen gekauften Produkte durch eine Warenkorbanalyse und die anschließende Platzierung dieser Waren in einem Regal nebeneinander. Dadurch wird die Wahrscheinlichkeit erhöht, dass beide Produkte gekauft werden. Andere datenwissenschaftliche Analysen können zur Vermeidung potenzieller Verluste eingesetzt werden.
Ein Beispiel wäre ein maschinelles Lernmodell, das nach Mustern von abwandernden Kunden sucht und automatisch die richtige Marketingkommunikation an diese Kunden sendet. Es könnte sich auch um Algorithmen handeln, die die Arbeit und die Zeit der Mitarbeiter im Unternehmen optimieren. So können sie beispielsweise die zu erledigenden Aufgaben nach einer Priorität einteilen, die sich nach dem Wert des Kunden und der Dringlichkeit der Aufgabe richtet. Ein guter Data Scientist, der in Ihrem Unternehmen beschäftigt ist, die Entscheidungsfindung im Unternehmen definitiv unterstützen wird.
Warum ist ein Data Scientist eine wichtige Position im Unternehmen?
Leider erfordert die Datenanalyse ein hohes Maß an Vertrautheit mit dem Thema, und ohne das richtige Fachwissen ist es schwierig, ein gutes Modell oder einen guten Algorithmus zu erstellen. Deshalb stellen die meisten Unternehmen Spezialisten ein, die sich mit dem Thema Datenerfassung, -verarbeitung und -analyse beschäftigen. Solche Spezialisten werden einfach als Data Scientists bezeichnet. Es ist jedoch zu bedenken, dass bei großen Analyseprojekten und der damit verbundenen Datenvisualisierung ein Spezialist nicht ausreicht, weshalb größere Unternehmen oft eine dedizierte Abteilung haben.
Was macht ein Data Scientist?
Die grundlegenden Tätigkeiten in der Data-Science-Abteilung sind die Pflege und Entwicklung der Datenarchitektur sowie der gesamte Bereich der Analytik und des Reportings. In kleinen und mittleren Unternehmen, die sich einen Wettbewerbsvorteil im Bereich Data Science verschaffen wollen, werden Projekte zur Implementierung einer analytischen Infrastruktur häufig von externen, auf diesen Bereich spezialisierten Unternehmen durchgeführt. Eine der Voraussetzungen für ein solches Projekt ist der Transfer von Expertenwissen, das für die Pflege der implementierten Umgebung erforderlich ist und das im Unternehmen von einem einzelnen Data Scientist oder einer kleinen Data-Science-Abteilung übernommen werden kann.
Data Engineering als Grundlage für Data Science
Um die Prozesse und Analysen im Bereich Data Science in Ihrem Unternehmen umzusetzen, benötigen Sie die richtige Datenarchitektur. Werkzeuge und Modelle benötigen Daten, die in geeigneter Weise erhoben und aufbereitet wurden, um darauf aufbauend Schlussfolgerungen ziehen zu können. Der gesamte Prozess, der der Data Science zugrunde liegt, heißt Data Engineering, und die Person, die in einem Unternehmen für diesen Bereich zuständig ist, wird als Data Engineer bezeichnet.
Was macht ein Data Engineer?
In den meisten Unternehmen sollte die Datenanalyse Daten aus mehr als einer Quelle umfassen, z. B. die Kombination von Transaktionsdaten mit Marketingdaten, um zu untersuchen, wie sich einzelne Kampagnen auf den Umsatz auswirken. Das Problem ist, dass diese Daten in verschiedenen Datenbanken und Quellen gespeichert sind, auf unterschiedliche Weise aggregiert werden und oft nicht leicht zu kombinieren sind. In der Praxis gibt es in einem Unternehmen in der Regel mehr als zwei Datenquellen, dazu zahlreiche Wörterbuch-Tabellen, komplexe Verknüpfungsbedingungen, und die Daten selbst sind oft verunreinigt.
Data Engineering sollte bereits in einem sehr frühen Stadium in den Prozess einfließen, oft schon bei der Entwicklung von Transaktionsdatenbanken und anderen Systemen zur Informationserfassung. Dadurch wird sichergestellt, dass die Daten von Anfang an so konsistent, sauber und analysierbar wie möglich sind.

Ein paar Worte über Data Warehouse
Tools und Methoden für das Data Engineering sind darauf ausgelegt, Daten aus Quellen zu extrahieren, sie ordnungsgemäß umzuwandeln und zu bereinigen und sie schließlich an einem Ort zu laden, an dem sie Datenanalyseprozessen unterzogen werden können. Solche Orte sind meist Data Warehouses, da die dort gespeicherten Datenbanken sehr lange aufbewahrt werden und das Warehouse neben analytischen Zwecken auch als Archiv dienen kann.
Ein gutes Data Warehouse sollte sich daher vor allem durch Skalierbarkeit, Langlebigkeit, Sicherheit und Schnelligkeit der Abfrageverarbeitung auszeichnen (letzteres ist im Bereich Data Science besonders wichtig).
ETL als integraler Bestandteil der Data Science
Die Prozesse und Werkzeuge, die zum Extrahieren, Transformieren und Laden von Daten in das Warehouse verwendet werden, werden als ETL (Extract, Transform, Load) bezeichnet. Unter Datentransformation versteht man vor allem Prozesse wie den Umgang mit Datenlücken, Verteilungen einzelner Variablen und die Aggregation der Menge auf die gewünschte Ebene (z. B. benötigen wir nicht unbedingt Daten zu jedem Ereignis, und eine Aggregation von Ereignissen in jeder Stunde ist ausreichend). Die Aggregation erleichtert die Speicherung sehr großer Datenmengen und ist oft sogar erforderlich, um mit der Datenanalyse und anderen Data-Science-Prozessen zu beginnen.
Explorative Analyse – Entdeckung von Mustern in Daten
Einer der Hauptbereiche der Data Science ist die explorative Analyse, die in erster Linie darauf abzielt, Muster und Beziehungen in Daten zu entdecken. Sie ist von großem praktischen Nutzen, da die entdeckten Beziehungen zum Vorteil des Unternehmens genutzt werden können. Ein Bereich der explorativen Analyse, mit dem sich ein Datenanalyst befasst, ist die Regressionsanalyse und die Untersuchung von Korrelationen zu Schlüsselvariablen.
Beispiele hierfür sind die Entdeckung von Investitionen, die einen starken positiven Einfluss auf Variablen – wie das Verkaufsvolumen oder die Anzahl der gekauften Produkte – oder einen negativen Einfluss auf die Produktionskosten haben. Mit diesen Informationen muss das Management nicht mehr raten, welche Investitionen am rentabelsten sind und welche nur scheinbar erfolgreich waren.

Der Datenanalyst muss sich auch mit der Datensegmentierung befassen
Eine weitere Aufgabe eines Datenanalysten bei der Durchführung einer explorativen Analyse ist das Clustering und die Segmentierung. Es geht darum, mithilfe geeigneter Algorithmen ähnliche Beobachtungen zu finden und sie in möglichst homogene Segmente zu unterteilen. Sie sollten differenziert werden. Eine adäquate Interpretation der Unterscheidungsmerkmale der Segmente kann erhebliche Verbesserungen im Datenmanagement bringen.
So kann die Kundensegmentierung beispielsweise zur Anpassung der Marketingkommunikation genutzt werden. Dies ist ein sehr wünschenswertes Verfahren, da unterschiedliche Werbematerialien an Stammkunden und andere an Kunden, die kurz vor dem Wechsel zur Konkurrenz stehen, gehen sollten. Natürlich kann es sehr viele Segmente geben, und innerhalb jedes Segments können weitere Mikrosegmentierungen vorgenommen und separate Modelle erstellt werden.
Warenkorbanalyse und sequentielle Analyse sind weitere Konzepte im Bereich Data Science
Der Bereich der explorativen Analyse umfasst auch die Warenkorbanalyse und die sequentielle Analyse, d. h. die Untersuchung von Produkten, die häufig in einem Warenkorb oder nacheinander gekauft werden, sowie die Klassifizierung von Beobachtungen auf der Grundlage ihrer Merkmale (z. B. ein Entscheidungsbaummodell zur Klassifizierung von Lieferanten in Bezug auf die Rentabilität) und die Sentimentanalyse, d. h. die Erfassung des Zufriedenheitsgrads mit dem gesammelten Feedback mithilfe von Algorithmen der künstlichen Intelligenz.
Die oben genannten Analysen sowie viele andere im Bereich der explorativen Analyse werden in der Regel mit Algorithmen oder Modellen des maschinellen Lernens durchgeführt. Sie werden von Firmen eingesetzt, um Wettbewerbsvorteile zu erzielen und wertvolle Erkenntnisse aus den gesammelten Daten zu gewinnen.
Was ist prädiktive Analytik?
Der zweite große Bereich der Data Science ist die prädiktive Analytik (eng. predictive analytics). Dabei geht es um die Entwicklung von Modellen des maschinellen Lernens, die auf der Grundlage eines Datensatzes in der Lage sind, den Wert einer Zielvariablen für jede Beobachtung unter bestimmten Annahmen vorherzusagen.
Mit anderen Worten: Diese Datenanalysetechnik ermöglicht es, zukünftige Werte vorherzusagen, die aus bekannten Gründen noch nicht in der Datenbankstruktur enthalten sind. Natürlich hat ein solches Modell nie eine 100%ige Genauigkeit, aber wenn die Ergebnisse nach der Messung zufriedenstellend sind, bedeutet dies, dass das Modell gut und nützlich ist.
Wann setzen wir prädiktive Analysen ein?
Predictive Analytics kann in erster Linie dazu verwendet werden, den Entscheidungsprozess zu automatisieren. Ein gutes Beispiel ist die Kreditwürdigkeitsprüfung, d. h. die Vorhersage, ob ein Kunde mit bestimmten Merkmalen einen Kredit zurückzahlen wird (d. h. de facto eine Entscheidung, ob ihm ein Kredit gewährt wird), oder ob der Kunde bald einen Kauf tätigen oder unsere Dienstleistungen nicht mehr in Anspruch nehmen wird.
Die Vorhersage kann auch kontinuierliche Variablen betreffen, wie den Kundenwert (CLTV) und die Preisgestaltung für Produkte oder Dienstleistungen. Ziel der Analyse ist es immer, auf der Grundlage der Vorhersage eine Entscheidung zu treffen, um sich an die Situation anzupassen (z. B. die richtige Marketingkommunikation zu versenden oder abwanderungsgefährdeten Kunden einen Rabatt zu gewähren).

Prädiktive Analytik und maschinelles Lernen
Die prädiktive Analytik basiert in der Regel auf maschinellem Lernen. Das bedeutet, dass ein Algorithmus eine Entscheidung über einen vorhergesagten Wert auf der Grundlage früherer Lernprozesse trifft. Das Modell erhält einen Trainingsdatensatz, der relevante Informationen zusammen mit dem Ergebnis der Zielvariablen enthält.
Nachdem sich der Algorithmus damit vertraut gemacht hat, für welche Konfigurationen der anderen Variablen ein bestimmter Wert einer bestimmten Variablen genommen wird, kann er feststellen, welche Variablen einen signifikanten Einfluss auf diese Variable haben und in welchem Ausmaß. Wenn also ein Datensatz ohne einen bestimmten Wert der Zielvariablen vorliegt, kann es diesen auf der Grundlage der anderen Beobachtungen, die ihm während des Lernprozesses zur Verfügung gestellt wurden, sozusagen „vorhersagen“.
Verständnis der prädiktiven Analytik und Data Science in der Praxis
Dies ist vergleichbar mit einem Angestellten, der nach Prüfung tausender früherer Kreditanträge beurteilen kann, ob dieser Kredit bei einem neuen Antrag gewährt werden kann. Der Unterschied besteht darin, dass das Modell in relativ kurzer Zeit aus Hunderten von Millionen von Beobachtungen lernen kann, wenn die Datenarchitektur entsprechend angepasst ist.
Die Algorithmen des maschinellen Lernens selbst sind vielfältig, und jeder lernt auf eine andere Art und Weise. Es ist schwer, ein einheitliches Modell zu finden, das sich in jedem Fall als das beste herausstellen würde. Deshalb besteht die Aufgabe von Data Scientists darin, die richtigen Algorithmen zu implementieren und ihre Parameter entsprechend zu wählen, dann die Ergebnisse zu vergleichen und den besten Algorithmus für einen bestimmten Fall auszuwählen.
Es gibt auf dem Markt Auto-ML-Tools (ML -Machine Learning) zur Automatisierung dieser Prozesse, die in der Lage sind, mit Hilfe künstlicher Intelligenz Parameter von Modellen auszuwählen, aber eine individuelle Herangehensweise an das Thema und die Anpassung des Modells an die Besonderheiten der Firma führt immer zu besseren Ergebnissen, weshalb ein mit dem Thema vertrauter Data Scientist so wichtig für den gesamten Prozess ist.
Automatisierung der Arbeit im Bereich Data Science – Implementierung von Modellen
Die Erstellung eines guten Modells erfordert eine Menge Arbeit, die darin besteht, den Datensatz richtig vorzubereiten, zu prüfen, ob alle Annahmen erfüllt sind, mehrere Modelle zu erstellen, sie dann zu vergleichen und das beste auszuwählen.
Diese Arbeit muss jedoch nicht jedes Mal gemacht werden, wenn wir ein Modell auf neue Daten anwenden wollen, solange diese sich nicht wesentlich von den Daten unterscheiden, auf denen der Algorithmus trainiert wurde. Daher werden die meisten korrekt erstellten und gut funktionierenden Modelle “ in der Produktion “ implementiert, d.h. sie werden so programmiert, dass sie von Zeit zu Zeit automatisch auf neu im Lager erscheinende Daten angewendet werden.
Ein richtig kodierter Algorithmus ist sogar in der Lage, das Modell von Zeit zu Zeit automatisch neu zu berechnen, d. h. mehrere Versionen zu erstellen und die beste auszuwählen. Dies kann nützlich sein, da sich in den meisten Firmen das Umfeld und damit auch die Daten ändern. Ein Modell, das auf Daten trainiert wurde, die unter bestimmten Umständen generiert wurden, wird bei neuen Daten, die möglicherweise völlig anders sind, nicht gut funktionieren.
Ein korrekt implementiertes Modell sollte daher von Zeit zu Zeit automatisch neu berechnet und angepasst werden und ständig auf neu generierte Daten angewendet werden. Wie oft dies geschieht, hängt natürlich von der uns zur Verfügung stehenden Rechenleistung ab.
Wie sieht Data Science in einem analytisch entwickelten Unternehmen aus?
In einem analytisch ausgereiften Unternehmen, in dem Data Science auf einem hohen Niveau entwickelt ist, werden viele verschiedene Modelle implementiert. Man kann sagen, dass sie miteinander „kooperieren“, d.h. sie profitieren gegenseitig von den zusätzlichen Informationen, die sie erzeugen.
Beispielsweise kann ein Kundensegment aus einem Segmentierungsmodell eine wertvolle Eingangsinformation für ein prädiktives Modell sein, das für die Vorhersage des Kundenwerts zuständig ist. Es ist also keine leichte Kunst, ihre Auffrischung so zu programmieren, dass das gesamte Ökosystem reibungslos und korrekt funktionieren kann.
Data-Orchestrierung kommt zur Rettung
Dies ist besonders wichtig, wenn die uns zur Verfügung stehenden Ressourcen an Rechenleistung begrenzt sind. Aus diesem Grund werden häufig spezielle Tools, so genannte Orchestratoren, eingesetzt, mit denen sich planen lässt, wann der Server den jeweiligen Prozess startet, angefangen beim ETL, über das Laden der Daten in das Warehouse, das Herunterladen in das Modell, die Neuberechnung und die Rückgabe der Ergebnisse an das Warehouse.
Natürlich kann es sein, dass das Data Warehouse bei steigendem Datenvolumen wachsen oder mehr Server für die Modellierung bereitstellen muss. Das kann durch die Verlagerung der gesamten Datenarchitektur in die Cloud gelöst werden, wo wir jederzeit zusätzlichen Platz oder Rechenleistung mieten können, wenn unser Bedarf wächst.
Wie geht Data Science mit riesigen Datenmengen um?
An dieser Stelle sollten wir auch erwähnen, was getan werden kann, wenn viele Daten anfallen und einzelne Recheneinheiten nicht in der Lage sind, diese in einer zufriedenstellenden Zeit zu verarbeiten. Ein Beispiel hierfür ist die Analyse von Bildern, Tönen oder großen Datensätzen, die beispielsweise aus Website-Protokollen stammen.
In einer solchen Situation ist der Einsatz von Big-Data-Tools erforderlich, die z. B. mit Hilfe von Map-Reduce-Algorithmen die Datenverarbeitungsaufgaben auf viele miteinander verbundene Server verteilen und die Ergebnisse zu einem Ganzen zusammenfassen. Auf diese Weise können die Daten um ein Vielfaches schneller verarbeitet werden, wobei die Geschwindigkeit von der Anzahl der eingestellten Server abhängt. Mit Big-Data-Lösungen können Sie Data-Science-Algorithmen auf sehr große Datensätze anwenden.
Umsetzung von Data Science in die Praxis
Der letzte Schritt besteht darin, die zusätzlichen Informationen zu nutzen, die wir mit Hilfe von Data Science erhalten. Natürlich können Sie die Analyseergebnisse selbst überprüfen und entsprechende Schlussfolgerungen daraus ziehen, aber der Schlüssel zu einem agilen und reaktionsschnellen Unternehmen liegt darin, auch diesen Prozess zu automatisieren.
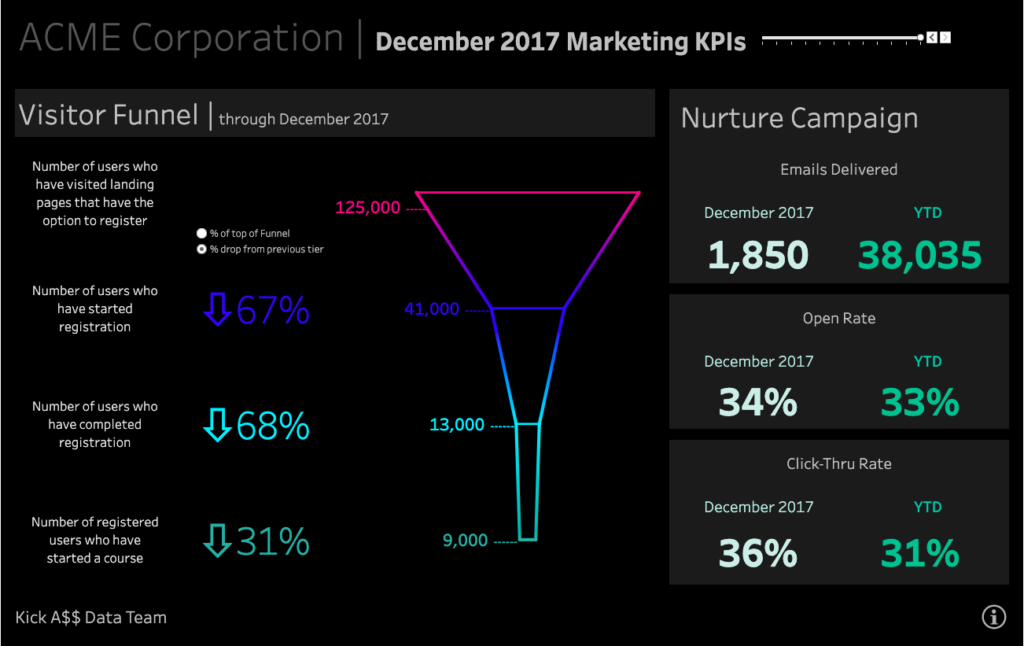
Hier gibt es unterschiedliche Lösungen – im Falle einer explorativen Analyse ist es zum Beispiel eine gute Praxis, die Schlussfolgerungen auf einem Dashboard zu visualisieren. Hierfür können spezielle Business Intelligence-Tools (z.B. Tableau) eingesetzt werden.
Damit haben die Entscheidungsträger eine schnelle und leicht zu interpretierende Schlussfolgerung zur Hand. Ein Beispiel wäre ein Diagramm oder eine Tabelle, in der die Ergebnisse einer Warenkorbanalyse oder eine sequentielle Analyse so klar wie möglich dargestellt werden.
Einsatz von Data Science im Geschäft
Die zweite Möglichkeit besteht darin, die Ergebnisse von Modellen mit Entscheidungscharakter zu verwenden. Natürlich können diese Informationen auch in BI visualisiert werden, aber der eigentliche Wert liegt in der automatischen Nutzung im Unternehmen.
Meistens geht es darum, die vom Modell erhaltenen Informationen an das entsprechende System weiterzuleiten, das diese Informationen in der richtigen Weise verwenden wird. Ein Beispiel hierfür ist die Übermittlung von Informationen über ein Kundensegment oder dessen wahrscheinliche Abwanderung an das CRM-System, wo Aufgaben für die Mitarbeiter erstellt und der automatische Postversand angepasst werden.
Auf diese Weise wird der Wert des Wissens aus Data Science automatisch ausgeschöpft und das Unternehmen erzielt einen Wettbewerbsvorteil, ohne unnötige Ressourcen zu engagieren.




